As a data scientist in the retail banking sector, it is natural that I do a lot of customer segmentations. Recently I was assigned to investigate on what kind of behavior our investment fund customers exhibit online, I used Gaussian mixture models to see what kind of “in between” After the project was concluded I decided to write a blog about Gaussian mixture as I thought the theory was quite interesting.
Background
Suppose now we are given the following data.
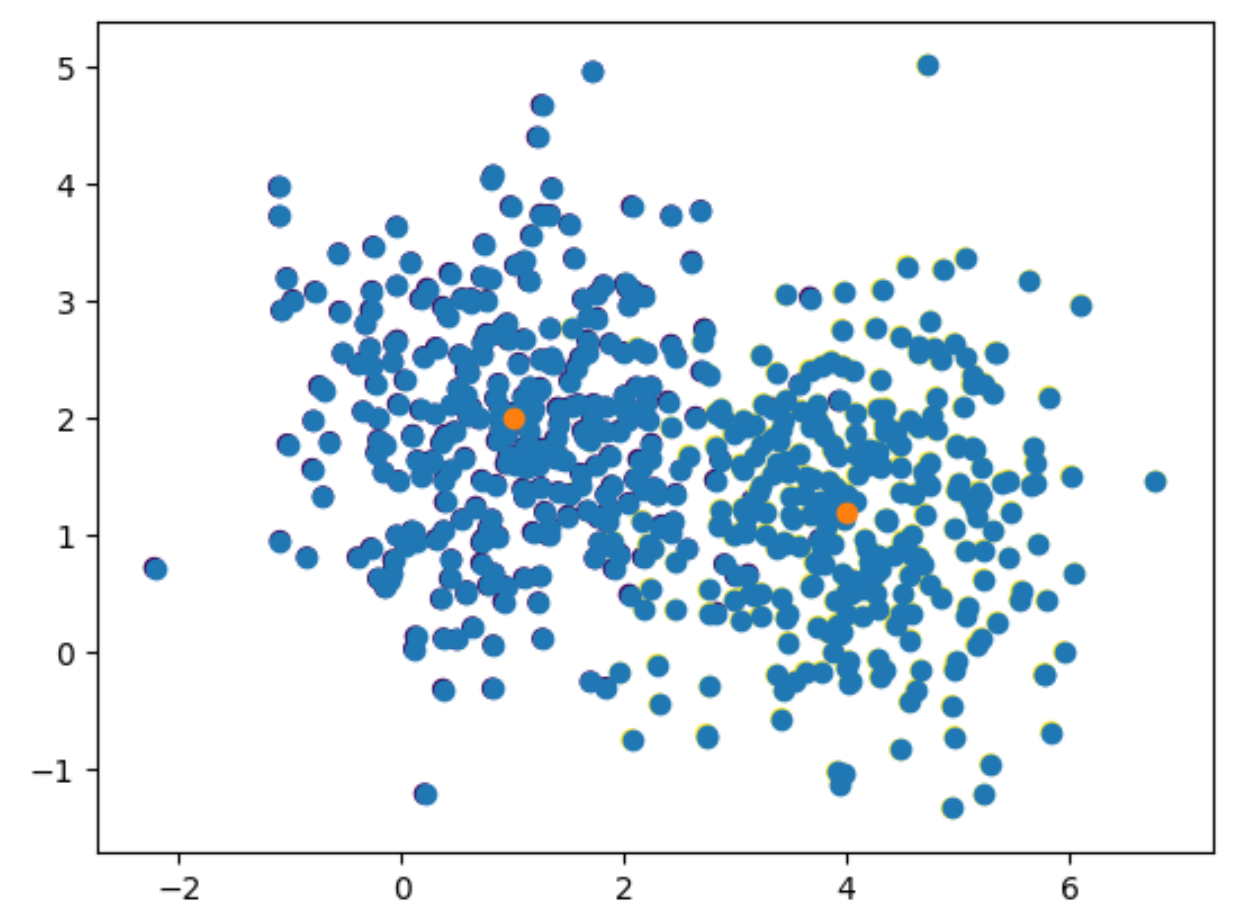
It is quite clear that there are two distinct distributions that generated the data. If this observation is correct, one question of immediate interest is what are the two distributions? Let’s assume that indeed there were only 2 distributions in the generation process. So that for an individual data point, it’s density is
where $\pi$ is the weighting of the first distribution, often called the responsbility of first distribution generating $x$, same interpretation is applied to $(1-\pi)$, $z_k$ an indicator of the components.
Note that in the most commonly used cluster algorthm K-Means, the responsibility is binary, meaning that a data point either came from a particular component or it did not, this can affect how we interpret the datapoints that are “in between” geometrically.
To loosen the notation as well as generalize the results we will obtain, let’s assume we have $K$ components instead, so the density is then
Method
We know not how $p(x\mid z_k)$ looks like at this point. But some assumptions can be made to help us estimate the true distribution, for example, let’s assume that $p(x\mid z_k)$ came from some parametric family of distributions so that $p(x\mid z_k) = p(x\mid z_k, \theta)$. Furthermore, let’s further assume that the components are Gaussians so that $p(x\mid z_k, \theta) = \mathcal{N}(x; \mu, \Sigma) $
Once we have that, we can try to use MLE to estimate the parameters that define this distribution. Recall the join distribution of n independent observations is
the log liklihood is then
This is quite difficult to maximize, the derivatives are not nice and might cause numerical instability.
Jensen’s inequality
It turns out, we can maximize a lower bound of (1) by invoking the Jensen’s inequality
In the language of statistics, this means that $f(\mathbb{E}[X]) \leq \mathbb{E}[f(X)]$.
To use this inequality on our log liklihood, notice that we already have the form required by the theorem, since $\sum \pi_k = 1$. However, using the inequality directly would restrict our model’s flexibility at choosing which component the data was generated from (linear dependence on the $\pi_k$).
So let’s introduce another distribution to take care of the weighting of a cluster for each sample, call it $Q(z_n=k)$
Tight bound - E step
$Q(Z)$ can be any disitribution in theory, although some choices of $Q$ are better than other ones. In particular, if we can make the above lower bound tight (the log liklihood is exactly equal to the lower bound) by choosing the right $Q$, then we can get some nice properties out of it.
To find such $Q$, we take at the difference between $\log p(X\mid \theta)$ and $l$. For a single data point x, we have
Since the KL divergence is non-negative, it is sufficient to set
to attend a tight bound. In our optimization procedure, this is called the E step or Expectation step.
The $Q$ we have acquired will help us prove the convergence of our iterative algorithm later.
Maximization - M step
It’s time we carry out the maximization, for this particular problem of fiitting mixture of Gaussians, some matrix calculus identities will be useful, refer to this SO page for more details.
Recall the formula for a multivariate Gaussian distribution
Refering back to the optimization objective (2), our $l$ now becomes
The respective optima are
For the $pi_k$, we need to apply some constraints for them to be proper distributions, they are $\sum_k \pi_k = 1$ and $\pi_k\geq 0 :\forall k=1\cdots K$. Using the KKT conditions, we solve the following system of equations
Now to actually solve the constrained optimization problem
Summary of EM algorithm

Implementation of GMM EM in Python
In this implementation, I used some scipy functions for convenience, they can be swapped out to make it purely numpy based.
Experimentation
I have generated a dataset that came from three distributions, these are generated with labels so we can assess the quality of our clustering directly.
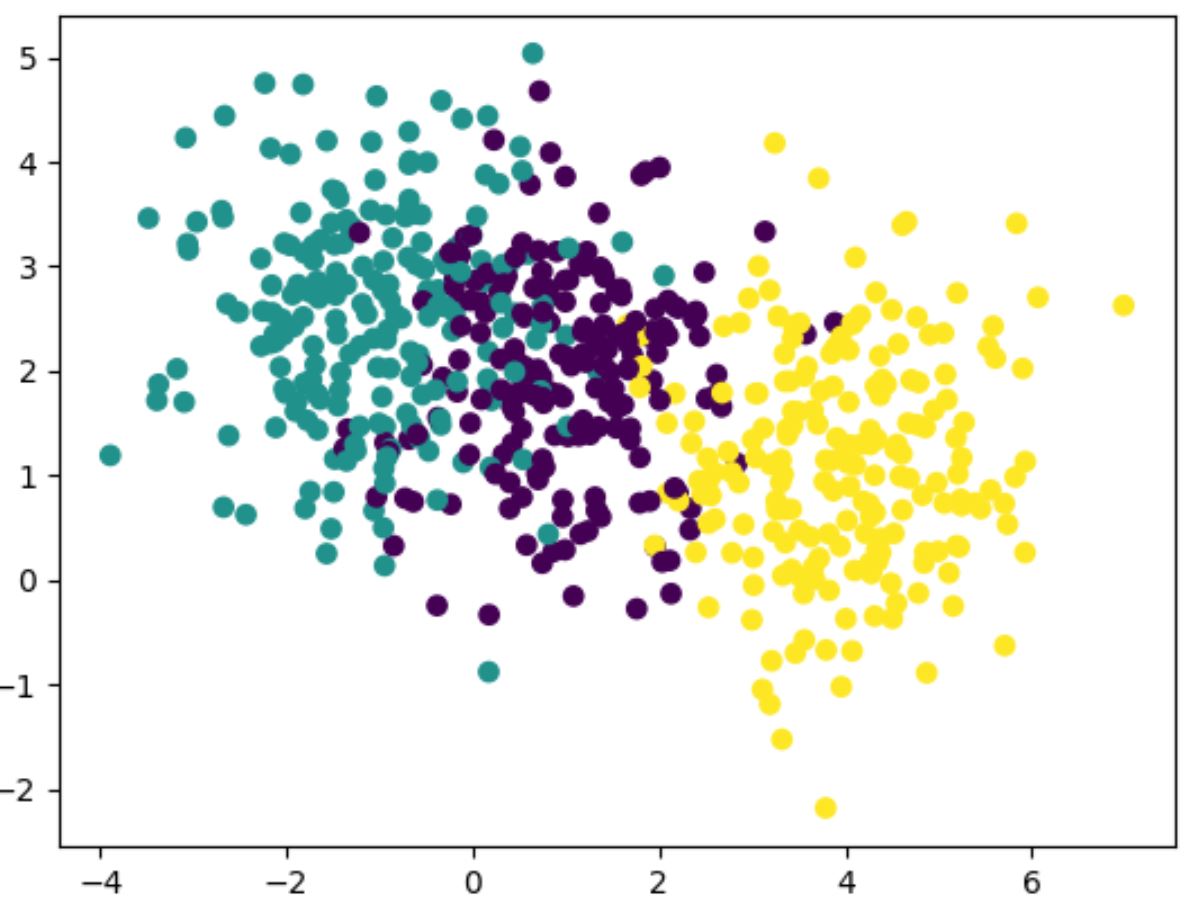
I ran GMM for 60 iteration and return a classfication report from sklearn. The number of iteration can be determined by performing validation on lower bound provided in (2), or perform early stopping.
| Label | Precision | Recall | f1-score | Support |
|---|---|---|---|---|
| 0 | 0.90 | 0.50 | 0.67 | 51 |
| 1 | 0.76 | 0.94 | 0.84 | 51 |
| 2 | 0.84 | 0.91 | 1.00 | 48 |